Notes
Origin
Frustrated by limited Retrieval-Augmented Generation (RAG) pipelines that only handle one document at a time? Buckle up, because Agentic RAG is here to unlock the power of multi-document retrieval!
对一次只能处理一个文档的有限检索增强生成(RAG)管道感到沮丧?系好安全带,因为 Agentic RAG 将释放多文档检索的威力!
In this continuation of our Agentic RAG series, we’ll dive into using the multi-step reasoning capabilities we explored previously, but this time across a diverse collection of documents.
在本篇 Agentic RAG 系列的续篇中,我们将深入探讨如何使用我们之前探索过的多步骤推理功能,但这一次是在不同的文档集合中使用。
Here’s the exciting part: Imagine an intelligent agent that can sift through a treasure trove of information. You ask a question, and this agent seamlessly directs you to the most relevant document for the answer. Agentic RAG makes this a reality!
令人兴奋的部分来了:想象一下,一个智能代理可以在信息宝库中进行筛选。你提出一个问题,这个代理就会无缝地将你引导到最相关的文档中寻找答案。代理 RAG 让这一切成为现实!

Image By Code WIth Prince
图片来源:Code WIth Prince
We’ll unveil the secrets behind this approach. We’ll see how to create a network of document-specific “information vaults” and empower an agent to navigate them. Finally, we’ll witness how this powerful system leverages traditional RAG procedures to unearth the answers you seek, no matter which document holds the key.
我们将揭开这种方法背后的秘密。我们将看到如何创建一个由特定文档组成的 “信息库 “网络,并授权代理浏览这些信息库。最后,我们将见证这一功能强大的系统如何利用传统的 RAG 程序,为您找到所需的答案,无论哪份文件都是关键所在。
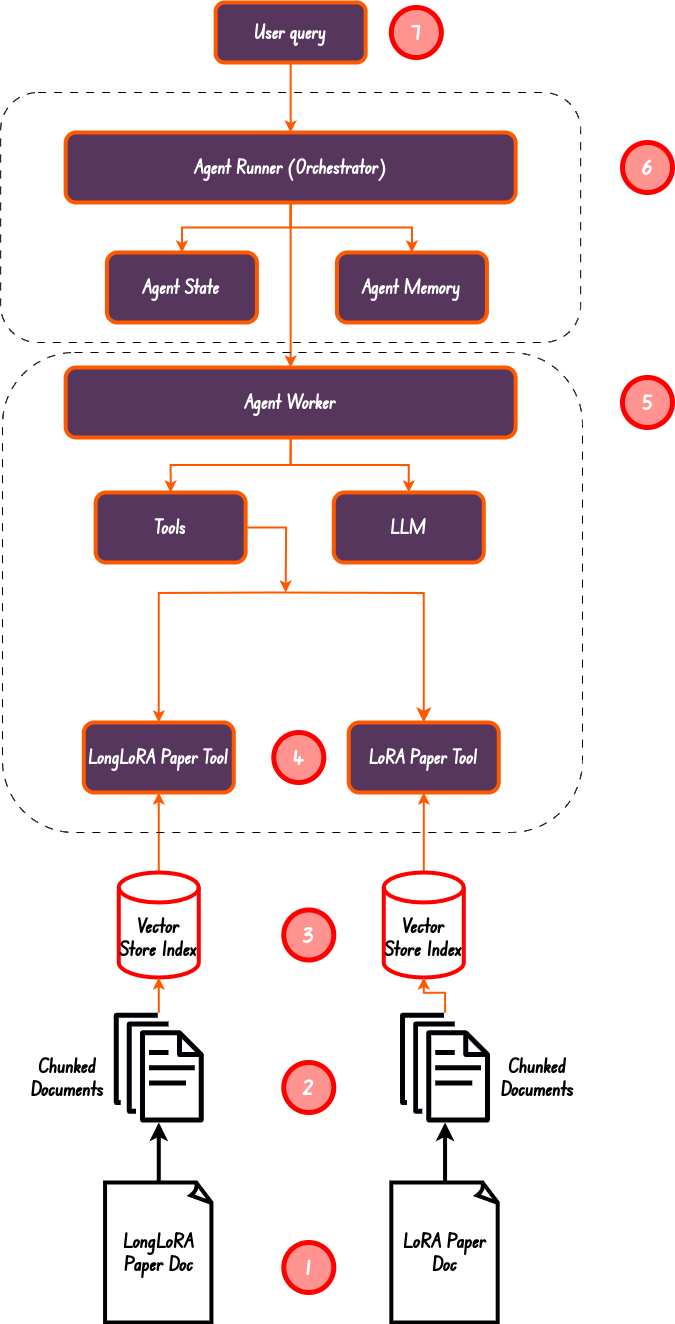
Image By Code With Prince
图片来源:Prince 代码
Let’s get started with implementing an Agentic RAG pipeline to chat with multiple documents.
让我们开始实施 Agentic RAG 管道,与多个文档聊天。
Setup Environment 设置环境
The first step we’ll take is to setup our development environment and get it ready to code. We’ll be using the same environment we setup from the first article. I’ll just create a new ipynb file for this particular lesson.
我们要做的第一步是设置我们的开发环境,并为编码做好准备。我们将使用第一篇文章中设置的相同环境。我将为本课创建一个新的 ipynb 文件。
Image By Code With Prince
图片来源:Prince 代码
New Download File 新下载文件
We’ll also use a new file that you can download from here, this file in my case is called longlora_efficient_fine_tuning.pdf
我们还将使用一个新文件,您可以从这里下载该文件,在我的案例中,该文件名为 longlora_efficient_fine_tuning.pdf
Updated utils.py 更新 utils.py
We’ll also need to update the utils.py file to host a new function: create_docs_tool . This new function will enable us to create query engines for a summary and vector query engines.
我们还需要更新 utils.py 文件,以容纳一个新函数: create_docs_tool .这个新函数将使我们能够创建摘要查询引擎和矢量查询引擎。
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SummaryIndex, VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
from typing import Tuple
async def create_router_query_engine(
document_fp: str,
verbose: bool = True,
) -> RouterQueryEngine:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the the Lora paper."
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=verbose
)
return query_engine
async def create_doc_tools(
document_fp: str,
doc_name: str,
verbose: bool = True,
) -> Tuple[QueryEngineTool, QueryEngineTool]:
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=[document_fp]).load_data()
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)
# summary query engine
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
# vector query engine
vector_query_engine = vector_index.as_query_engine()
summary_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_summary_query_engine_tool",
query_engine=summary_query_engine,
description=(
f"Useful for summarization questions related to the {doc_name}."
),
)
vector_tool = QueryEngineTool.from_defaults(
name=f"{doc_name}_vector_query_engine_tool",
query_engine=vector_query_engine,
description=(
f"Useful for retrieving specific context from the the {doc_name}."
),
)
return vector_tool, summary_tool
Creating Vector And Summarization Tool
创建矢量和摘要工具
We are going to use the function we just created above to create vector and summarization tools for each of the papers we have setup.
我们将使用上面刚刚创建的函数,为我们设置的每篇论文创建矢量和摘要工具。
import dotenv
%load_ext dotenv
%dotenv
import nest_asyncio
nest_asyncio.apply()
papers = [
"./datasets/lora_paper.pdf",
"./datasets/longlora_efficient_fine_tuning.pdf"
]
from utils import create_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Creating {paper} paper tool.")
path = Path(paper)
vector_tool, summary_tool = await create_doc_tools(doc_name=path.stem, document_fp=path)
paper_to_tools_dict[path.stem] = [vector_tool, summary_tool]
paper_to_tools_dict
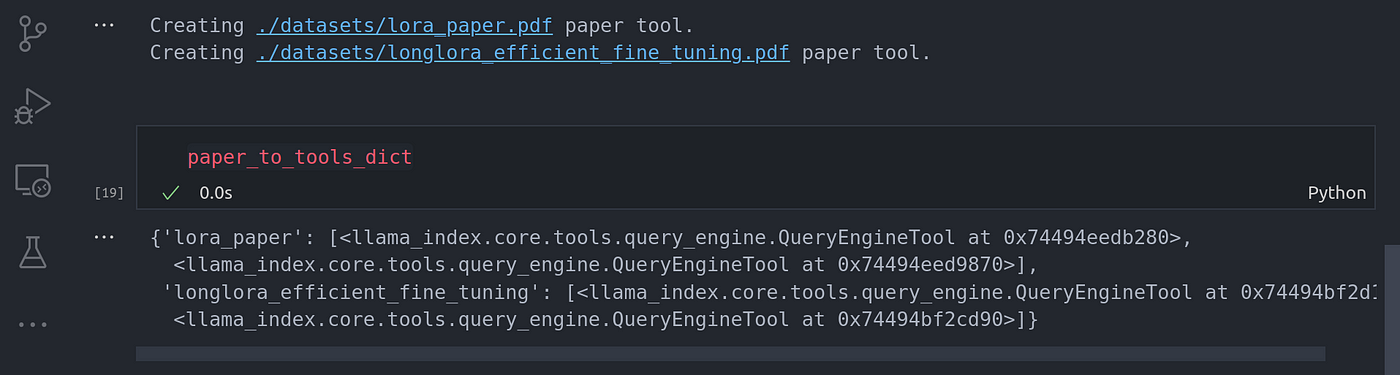
Image By Code With Prince
图片来源:Prince 代码
initial_tools = [t for paper in papers for t in paper_to_tools_dict[Path(paper).stem]]
print(str(initial_tools))
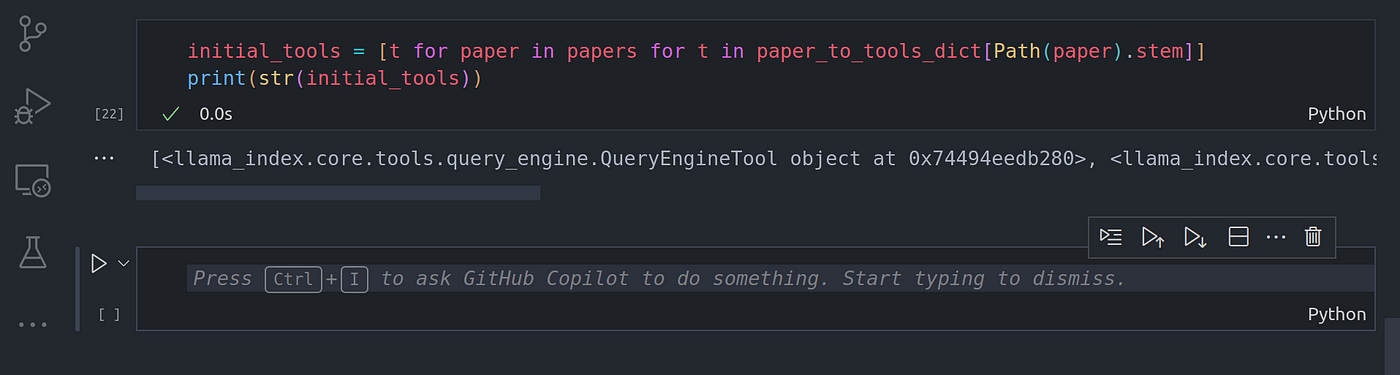
Image By Code With Prince
图片来源:Prince 代码
len(initial_tools)

Image By Code With Prince
图片来源:Prince 代码
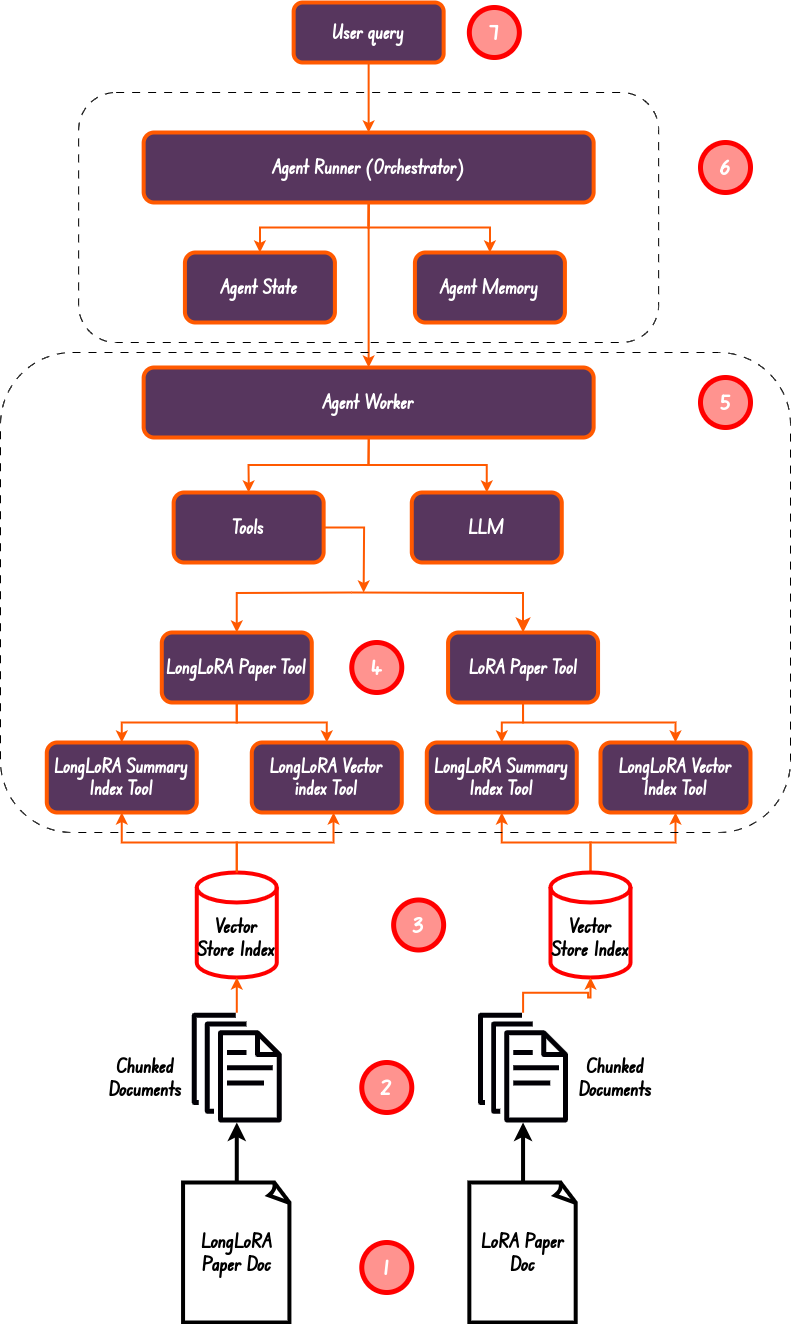
Image By Code With Prince
图片来源:Prince 代码
From the diagram above, we have done step 1 through step 5. We have created a summary and vector index, this making sure we have 4 tools in total, which is also the length of the tools list.
从上图来看,我们已经完成了步骤 1 到步骤 5。我们创建了摘要和矢量索引,这确保我们总共有 4 个工具,这也是工具列表的长度。
Creating The Agent Worker
创建代理 Worker
The agent worker is the Orchestrator responsible for allocating work to the agent worker. This is step number 6 in the diagram above.
代理工作者是负责向代理工作者分配工作的协调者。这就是上图中的第 6 步。
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
initial_tools,
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Explain to me what is Lora and why it's being used."
"Explain to me what is LongLoRA and why it's being used."
"Compare and contract LongLoRA and Lora."
)
print(str(response))
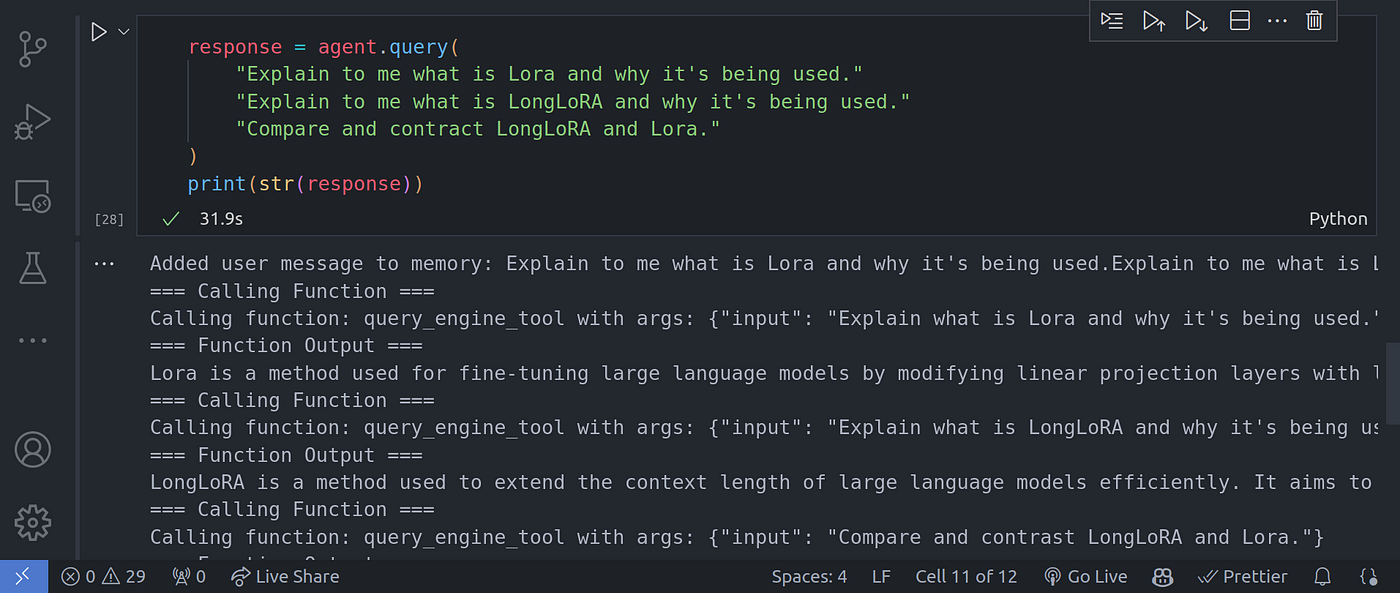
Image By Code With Prince
图片来源:Prince 代码
More Advanced Multi-Document Agentic RAG Pipeline
更先进的多文档代理 RAG 管道
So far we have been able to use two documents and all works just fine. This leads to an issue with more documents being added. Imagine we had 20 documents that would be 40 different tools, that is abit wild:
到目前为止,我们可以使用两个文档,而且一切运行正常。这就导致了添加更多文档时的问题。试想一下,如果我们有 20 个文档,就会有 40 种不同的工具,这就有点疯狂了:
-
Overflow of context window: Adding more documents to the leads to more tools, adding more tool calls to the context window can lead to an overflow of the context window. Easiest way to address this is to add a sort of RAG to the tool section such that we perform some sort of retrieval on the tools first so see what tool(s) is well suited for the task at hand and then only feed that tool’s output to the LLM. We don’t want to pass too many tools into the context window, it’s better to retrieve the most relevant tools first then pass those to the LLM.
上下文窗口溢出:添加更多文档会导致更多工具,在上下文窗口中添加更多工具调用会导致上下文窗口溢出。解决这个问题的最简单方法是在工具部分添加一种 RAG,这样我们就可以先对工具进行某种检索,看看哪些工具适合手头的任务,然后只将该工具的输出输入 LLM。我们不希望向上下文窗口传递过多的工具,最好是先检索最相关的工具,然后将这些工具传递到 LLM 中。
-
Increase in costs: Stuffing tool many tools into the context window means more token usage on your end. I don’t know how deep your pocket is, but its better you send that money my way ;).
增加成本:在上下文窗口中塞入过多的工具意味着要使用更多的令牌。我不知道你的口袋有多深,但最好还是把钱寄给我吧;)。
-
LLM can get confused: Research has shown that in most cases, LLMs mostly remember things at the very beginning of the context window and those at the end, the contest in the middle can get forgotten by the LLM. This means despite the large context windows LLMs have today like Gemini with its 1 million tokens, it still may suffer from this.
LLM 容易混淆:研究表明,在大多数情况下,LLMs大多会记住上下文窗口开头的内容和结尾的内容,中间的竞赛内容可能会被 LLM 遗忘。这意味着,尽管 LLMs 如今拥有很大的上下文窗口,如拥有 100 万个令牌的双子座,但它仍然可能会受到这种情况的影响。
The solution to this is to perform retrieval on the tools to get the most relevant tools and pass these relevant tools into the reasoning loop prompt of the agent. At least this is what Llama-index has done in the background. They provide a tool retrieval that helps with this.
解决这个问题的办法是对工具进行检索,以获得最相关的工具,并将这些相关工具传递到代理的推理循环提示中。至少 Llama-index 在后台就是这么做的。他们提供的工具检索有助于实现这一点。
Multi-document Agentic RAG Implementation With Tool Retrieval
带工具检索的多文档代理 RAG 实现
To implement this, I would advise you to download more documents. In my case, I’ll only use the existing documents we have been working with so far. You can use this code to download more documents if you want to.
要实现这一点,我建议您下载更多的文件。在我的例子中,我将只使用我们目前使用的现有文档。如果你想下载更多文档,可以使用这段代码。
urls = [
"https://arxiv.org/pdf/2106.09685"
]
papers = [
"lora_paper.pdf",
]
# poetry add wget
import wget
for url, paper in zip(urls, papers):
!wget "{url}" -O "{paper}"
Make sure you run the command to install wget
请确保运行了安装 wget 的命令。
$ poetry add wget
But for the sake of simplicity and saving everyone time, I’ll stick to using the documents we have been already using:
但为了简单起见,也为了节省大家的时间,我将坚持使用我们已经使用过的文档:
papers = [
"./datasets/lora_paper.pdf",
"./datasets/longlora_efficient_fine_tuning.pdf"
]
from utils import create_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Creating {paper} paper tool.")
path = Path(paper)
vector_tool, summary_tool = await create_doc_tools(doc_name=path.stem, document_fp=path)
paper_to_tools_dict[path.stem] = [vector_tool, summary_tool]
tools_list = [t for paper in papers for t in paper_to_tools_dict[Path(paper).stem]]
print(str(tools_list))
Create the ObjectIndex that we’ll use for retrieval of the most appropriate tools:
创建 ObjectIndex ,我们将用它来检索最合适的工具:
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
tools_list,
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
retrieved_tools = obj_retriever.retrieve(
"Write me a summary of the LoRA paper."
"Write me a summary of the LongLoRA paper."
"Compare and contract LongLoRA and Lora."
)
print(str(retrieved_tools))
From these set of questions, we can view the tools that have been selected through retrieval:
从这组问题中,我们可以查看通过检索选出的工具:
for tool in retrieved_tools:
print(tool.metadata.name)
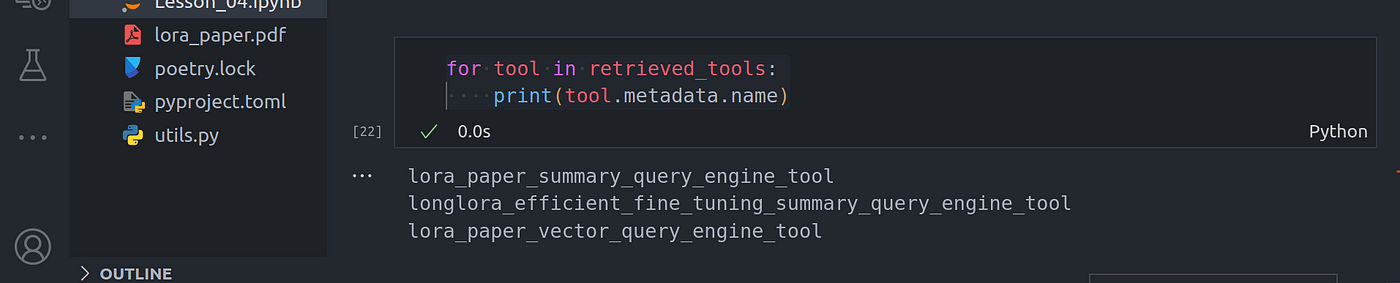
Image By Code With Prince
图片来源:Prince 代码
Creating The Agent 创建代理
We’ll need to create the agent runner and the agent worker:
我们需要创建代理运行程序和代理 Worker:
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt=""" \
You are an AI agent programmed to respond to questions based on a
specified collection of documents. Always utilize the tools available
to generate answers, ensuring that responses are based directly on the
provided materials rather than on any pre-existing knowledge. All your responses should be formatted in markdown text
""",
verbose=True
)
agent = AgentRunner(agent_worker)
We can then go ahead and call the agent:
然后我们就可以继续调用代理了:
response = agent.query(
"Write me a summary of the LoRA paper."
"Write me a summary of the LongLoRA paper."
"Compare and contract LongLoRA and Lora."
)
print(str(response))
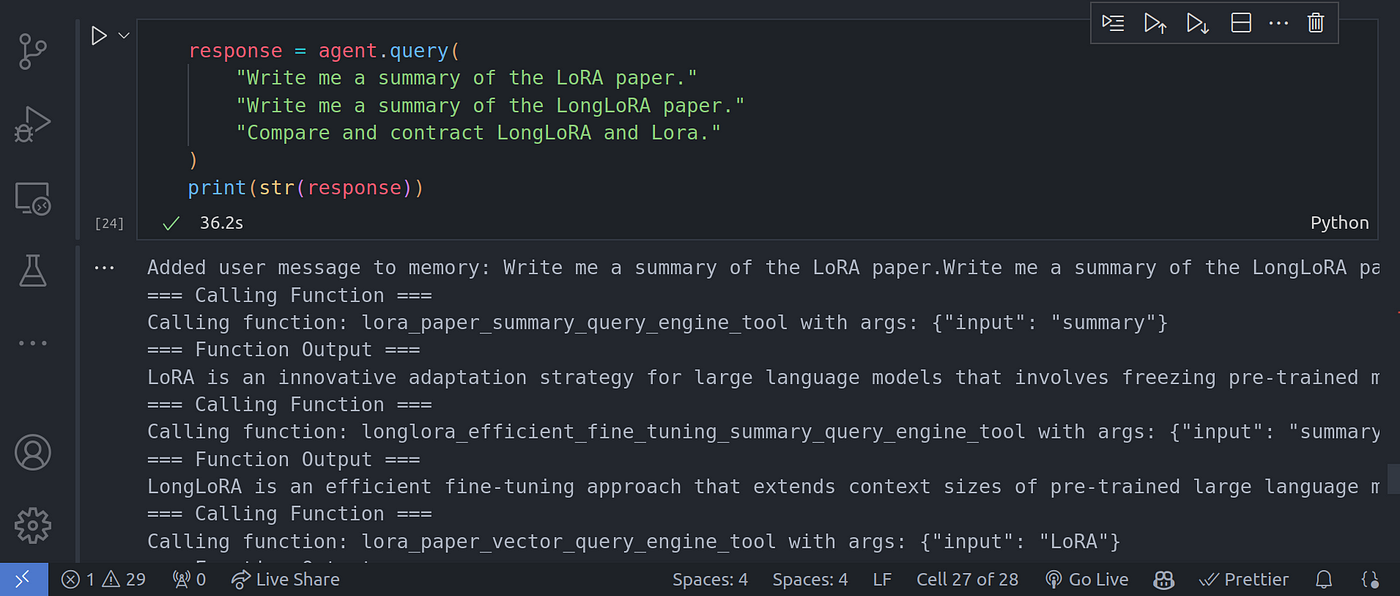
Image By Code With Prince
图片来源:Prince 代码
Image By Code With Prince
图片来源:Prince 代码
Conclusion 结论
Congratulations for making it this far. In this article post, we have gone over how to work with a multi-step reasoning loop over multiple documents in an agentic RAG system. We did not only see the high-level implementation, but also the low-level working of the multi-step reasoning loop.
恭喜您完成了这一步。在这篇文章中,我们介绍了如何在代理 RAG 系统中对多个文档进行多步推理循环。我们不仅看到了高层实现,还看到了多步骤推理循环的底层工作。
Hope this article now provides you with a clear understanding of an agentic multi-step reasoning capability over multiple documents.
希望这篇文章能让你清楚地了解代理多文档多步骤推理能力。
**Other platforms where you can reach out to me:
其他可以联系我的平台:**
**_Happy coding! And see you next time, the world keeps spinning.
编码快乐!下次再见,世界在继续转动。_**